
常见排序算法的原理和实现
冒泡排序冒泡排序的原理很简单,就是每次都把当前无序序列中最大(或者最小)的元素移动到序列的开头(或者结尾),之后再对除该元素之外的剩余序列做同样的操作。当所有的元素都冒泡完毕之后,整个序列就会变得有序。冒泡排序的过程正如它的名字一般,每次都把序列中最大的元素移动到末尾(假设我们选择了这种规则),这种操作就好像水中的泡泡不断地从水中浮到水面一般。冒泡排序的实现如下,简单观察就可以知道它的时间复杂度为O(n2)123456def bubble_sort(arr): length = len(arr) for i in range(length - 1): for j in range(length - 1 - i): if arr[j] > arr[j +..
更多
弄懂难缠的DFS算法和相关变种(Python实现)
前言这次不废话,直接接上次的BFS,直接来看DFS。 什么是DFS算法DFS,全名深度优先搜索 用大白话来说,其实就是 一条路走到黑,走不通再回来,直到无路可走 举个简单的例子,现在我们有一个树,就像下面这样 12345 A / \ B C / \ / \D E F G 假设我们要用DFS算法来进行遍历/搜索 它的步骤如下 从初始节点A出发,并且将A标记为已访问 查找A的一个临接顶点B。 如果B存在,继续执行访问,否则回退到上一步,继续查找临接顶点 将B标记为可访问,继续执行查找临界点D的操作 重复操作,直到所有的值都访问完了,无值可以访问为止。 那么,遍历树的顺序应该是 A -> B -> ..
更多
弄懂难缠的BFS算法和相关变种(Python实现)
前言这段时间频繁刷题,leetcode真的好难啊!!每次都他娘的做不出来,除了刷题,最近还在复习各种架构,或者是完成公司的开发。这些占据了我过多时间,所以blog其实一直想写,但是实在腾不出时间,今天在针对性刷leetcode的时候,对BFS/DFS有了一点别的感悟,所以就写一篇博客,作为自己的笔记,在记录的同时,也帮助其他兄弟少走弯路,希望,能够帮到大家。 什么是BFS算法?这些百度谷歌都搜的到,不过这里还是简单说一下吧 首先,BFS的全名,叫做广度优先搜索算法 搜索,顾名思义,是找寻某个东西,所以叫搜索,在写代码的时候,搜索,其实等同遍历,只是这个遍历是有条件的。 相对于BFS,它的条件是什么呢? 举个例子,有个迷宫,有两个点,你要从A 移动到..
更多用堆找出最小的 N 个数
不知道为啥,突然想水一篇很水的算法文章。 今天整理 MySQL 的笔记,看到了这样一句话: MySQL 在执行 ORDER BY x LIMIT n 这类语句,且 LIMIT 的数量有限时(比如只需要 3 条数据),MySQL 会尽量通过堆来构建优先队列,减少排序所需的时间。 这是堆的一个经典应用:从海量数据中找出最大(小)的 n 个数。 之前只用堆写过堆排,没有用堆处理过在线算法,所以就写了写。 用一句话概括这个算法:要找最小的数,就要构建大顶堆。 在处理数据时,我们会构建一个大顶堆 H,那么 H[0] 的值也就是当前数据中最小的 N 个数中的最大值,也就是第 N 小的数。 当处理新的数时,如果这个数小于堆顶的数,那么就把它变成堆顶,然后再对堆进行维护,以保证有序。 此算法的时间复杂度为 O(Ml..
更多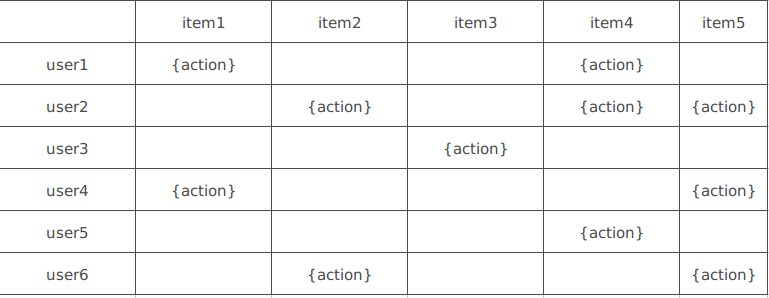
关于协同过滤的推荐算法
这个主题想写已经很久了 自从换了新部门之后 也没有写过前端 因为部门总共6个人 有两个前端 然后后端和算法人员不足 因为我技术比较强 就被安排到了新的任务 老大和我说 做数据和算法比前端有前途 话是这么说的 但是我从大一起开始写前端写了这么多年 突然让我去写其他的 那我前端领域的优势就没了啊 而且就算我继续算法这些写个三年四年 到时候仍然随便一个刚刚毕业的专门研究算法的就能把我干趴下了好吗 毕竟我也没怎么专门研究过这些东西 不过既然部门有任务安排 那只能写了 这段时间经历了 python从入门到精通 hbase从入门到精通 hadoop从入门到精通 什么kafka 什么zookeeper 让我作为一个前端大开眼界 有点偏主题了。。。。我的主要工作有三点..
更多